Different Design Frameworks for ML Based Fraud Detection
Published:
- Progression of Machine Learning Frameworks for Fraud Detection
- Group 1. Reputation Scores, Shared Data Networks and Pre-trained Models
- Group 2. Clustering and Anomaly Detection
- Group 3: Semi-supervised Learning, Active Learning
- Group 4. Supervised Classification Algorithms
- Takeaways
- Next up
If you are building fraud detection systems for your organization, the first step is to build the foundations as we previously discussed in the foundations of fraud detection systems.
You can set up a team of investigators, risk analysts, and engineers. The engineers create systems to collect and store data of all the users’ interactions with your web or mobile service. The data collected from users’ interactions might include HTTP headers, user agents (which can be used to extract device, OS and browser information), IP addresses (which can be used to extract location, internet provider, ASN etc.), transaction and payment information, time of activity, clickstream and much more. These data points will become essential for building machine learning based solutions later on. The investigators and risk analysts start finding suspicious activities and marking events that are confirmed to be fraud. These are additional data points that together with attributes collected on every user activity are the powerhouse of ML models. We will discuss what types of ML techniques can be used in different scenarios in the current post. And in next few posts, we will develop each of those models from scratch.

All that I described above doesn’t happen in a single day. Some organizations are at an early stage of data collection while others have large teams of analysts who are continuously blocking fraudsters. Naturally, the volume of data and confirmed suspicious activities are also different for different organizations. So in this post, we will discuss a high level mental framework for types of ML algorithms that can be implemented at different stages of organizational growth.
The following frameworks are segmented based on organization’s capability to retrive past user activity data and on the presence of known fraudulent activities to extract patterns from. From 1 to 4, there will be an upward trend in terms of capability to tackle fraud, but it will require time and manual efforts to reach there. Here is lay of the land:
Progression of Machine Learning Frameworks for Fraud Detection
| # | Collecting user activity data | Have examples of fraudulent activities | Use the following |
|---|---|---|---|
| 1 | No | No | Reputation Scores, Shared Data Networks/Consortium/Federated Learning, Pre-trained Models |
| 2 | Yes | No | Clustering, Anomaly Detection + All from Paradigm 1 |
| 3 | Yes | Yes, a little bit | Semi-supervised Learning, Active Learning + All from Paradim 2 |
| 4 | Yes | Yes, quite a bit | Supervised Classification Algorithms + All from Paradigm 3 |
Group 1. Reputation Scores, Shared Data Networks and Pre-trained Models
The question is, can you do better than traditional solutions like setting up rules or hiring investigators without having an access to the historical user activity data and without having knowledge of the activities that have been fraudulent in the past. The answer is, yes. You can try the following options to get the wheel rolling.

High Risk, IPv6, Artificial Intelligence, Collaborating In Circle.
These solutions are not limited to the lack of training data, but is also about the lack of time and budget to train models from scratch, or the absence of systems that store the user activity data.
A. Reputation Scores

Reputation scores are risk scores that represent the general riskiness of attributes associated with an online activity. These scores are provided by security systems that search for early signs of malicious behavior originating from multiple places on the internet.
The idea behind reputation scores is that malicious actors often try to attack multiple services using similar behavioral patterns and the same device, internet service, etc. That is, your organization is one of the potential targets among many. This hypothesis is not always accurate (i.e. sometimes malicious actors target specific organizations), but it provides a good start when you do not have the capability to train your own fraud detection models.
The common attributes for which you can find reputation scores are IP address, email address, phone number, or the user agent, with IP address being the most common one. IP reputation scores are made up from information like whether an activity is connected with proxy servers or not, whether the IP address has VPN service turned on, whether an IP is hosting malicious content, or whether it exhibits automated bot behavior. User agent reputation scores check whether certain user agents are command-line tools or not. Email address reputation scores might look at how many spams originated from an email address. You can use reputation scores for one or more attributes, depending on which ones you are able to connect with user activity.
If you would like to try out reputation scores for your use case, there are a number of paid reputation score providers. Some examples include DataVisor, TeleSign, Apivoid, Talos, MaxMind minFraud, and Microsoft Defender Threat Intelligence. Most of these providers have APIs that are quick to test or integrate with the sign-in or transaction pages, so that each sign-in or transaction first goes through a reputation check.
Now, the simplest way to use reputation score is to take the score and apply risk buckets to each transaction based on the scores. For example, block transactions with a risk score >90/100, send transactions with a score of 70-90 for another verification like 2nd factor auth or investigator review, and let other transactions pass through. Some score providers also give you recommendations about actions based on scores. You might also need to define your own notion of riskiness depending on the weights you want to assign to each attribute with an associated reputation score.
Note that the reputation scores have various limitations too and cannot tackle all types of modern fraud vectors. First, over time fraudsters have learned to circumvent reputation score-based systems to avoid detection. For example, the fraudsters rotate between different IP addresses or use ones that have virtually no history and reputation score providers have no data for those. Second, is that it has become increasingly difficult for score providers to monitor, evaluate, and assign a risk score to all IP addresses due to the sheer volume of available IP addresses. With IPv6, the number is approximately 340 undecillion. In addition, the reputation of an IP fluctuate frequently and the score providers have to refresh all scores at-least monthly. Third, and most important, the assumption that all frauds MOs have bad reputation of IP, email or user agent is often violated.
To tackle these limitations, your systems will have to advance over time and rely on using a wide range of signals. Despite their limitations, reputation scores are a valuable tool for organizations looking to improve their fraud detection capabilities. By integrating these into your fraud detection pipeline, you can gain a valuable early warning signal about potential fraud and take steps to mitigate it.
B. Shared Data Network, Consortium and Federated Learning Solutions

Also called Consortium, the shared data network is a secure system where a large number (like thousands) of global institutions pool the data of comfirmed malicious activities. If done securely, i.e. without impacting any institions’ data privacy, the consortium can be a really powerful tool where organizations come together to tackle fraud together and once one organization sees an attack vector, they share with others. Joining one such consortium is another option to improve your fraud detection capabilities.
Companies like payment gateway service providers and banks have a great headstart to create a fraud consortium. They already have payments data from multiple other companies and the knowledge of transactions that are blocked. So in a way, they have both data and labels that can be used to train fraud detection models that can provide risk score to all their consortium members. For instance, Falcon Intelligence Network by FICO is a large consortium of anonymized transactional and non-monetary data contributed by over 9,000 financial institutions worldwide.
You can choose one of the options among Falcon Intelligence Network, Microsoft’s fraud prevention network, Stripe’s Radar, Kount’ Identity Trust Global Network and use the consortium risk score in conjunction with authentication products in your overall fraud deterrence strategy.
The trust on the organization that is developing the consortium is of utmost importance. The consortium creator/moderator needs to have the highest standards in terms of keeping the data of their participants secure from leakage, retaining the user privacy of each member (maybe by only retaining encrypted data), not allowing any particpant member to extract information about users’ of other members and strong mitigations against data poisoning attacks.
For a secure and privacy preserving model training with a shared data network, Federated learning is an important emerging field of the machine learning that enables the models to be trained from different datasets located at different servers, without transfering the training data to a central server. It is decentralized model training that allows each organization’s data to remain on their local servers, reducing the possibility of data breaches while allowing the transfer of knowledge.
C. Pre-trained Models

The idea of pre-trained models is similar to transfer learning that we commonly discuss in the natural language and computer vision literature. The model trained on one corpus of dataset can be used to transfer the knowledge over another corpus of dataset with some fine tuning. While fine tuning of the pre-trained model on the new data corpus is an important step, if it is not possible to do so, as in the case where we don’t have any historical data to fine tune with, the pre-trained model still has a lot of useful signals. For fraud detection, the companies like Ravelin provide solutions on the similar lines with their micro model architecture. You can use one of their pre-trained models that have the knowledge of fraud patterns.
Group 2. Clustering and Anomaly Detection

Most companies even without risk/fraud teams collect user activity data for the business purposes like targeted marketing, personalizations and basic account access handling. This category of solutions can be employed when you do not have any fraud labels but have been collecting user activity data.
A. Clustering

In order to find clusters, behavioral (e.g. number of clicks), frequency (e.g. number of times a user logged in within last 1 hour) and profiling (e.g. location of order) attributes of users and their associated activities are used, but any information on confirmed fraud labels is not required. The clustering approaches like Hierarchical clustering, K-means and DBSCAN are common in fraud domain. More recently, Graph based clustering methods are used to capture complex relationships that other approaches would miss.
Clustering can be very useful in certain fraud attack scenarios, as following:
1. Find organized frauds:
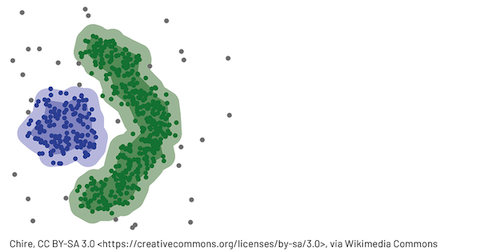
Reference: Identifying Financial Fraud With Geospatial Clustering by Databricks
Fraud coordinated by groups of professional fraudsters that are part of a group and act at scale to maximize their gain is referred to as organized fraud. Organized fraud relies on coordinated events called fraud campaigns. During a fraud campaign, several orders are placed over a limited period of time by a small group of fraudsters using different electronic identities.
In such cases, analyzing each activity in isolation and independent of each other is not an effective solution to find and stop the fraud attacks. Instead, you can create clusters based on user behavior and profiles. Organized attacks would fall into high density clusters compared to the legitimate users. Based on the clustering output, you can apply additional screening steps in abnormally high density clusters (i.e. having a large number of activities in a cluster)
2. Bulk investigate suspicious activities:
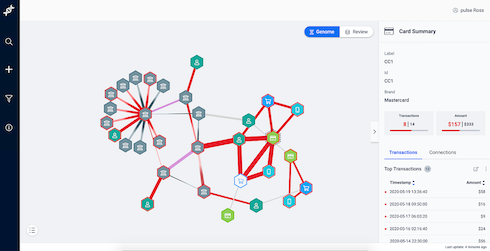
Reference: Empowering Fast Graph Visualizations for Fraud Detection (or Why We Built Our Own Graph Database by Francisco Santos
Rather than making your investigators look at each activity indepndently, you can use clustering to make their lives easier and surface a group of events that invesigators can look at. If one event in a group is fraudulent, there are high chances that other events too in the same group are fraudulent and displaying such events as a group makes it easy to investigate at scale and take bulk actions. Such functionality can increase investigator’s efficiency and provide an overall boost to your fraud detection capability. You can even go a step further and provide reasons why your clustering algorithms think that certain events are connected. For example, it might show that N orders are connected because they are being generated by same card number.
B. Anomaly Detection/ Outlier Detection

Outlier Detection (OD) (or Anomaly Detection) is the task of identifying abnormal objects from the population of normal objects. OD is employed in fraud detection sub-fields like intrution detection, malicious URL detection, backdoor attack detection, fake reviews and credit card fraud detection. Fraudsters are expected to show unusual behaviors like unusually high volume of traffic, unusual patterns of failed logins, multiple promotions from the same device etc. OD algorithms can be used to identify activities that exhibit the following unusual patterns:
1. Account activity: Fraudulent accounts may exhibit unusual activity patterns, such as making large purchases or withdrawing large sums of money.
2. Device usage: Fraudsters may use devices that are not typically used for legitimate transactions, such as public Wi-Fi networks or VPNs.
3. Location: Fraudulent transactions may originate from unusual locations, such as countries where the customer does not live or travel.
4. Payment method: Fraudsters may use payment methods that are not typically used for legitimate transactions, such as gift cards or prepaid cards.
5. Transaction amount: Fraudulent transactions may be for unusually large amounts of money.
6. Transaction frequency: Fraudulent transactions may occur more frequently than normal transactions.
7. Transaction time: Fraudulent transactions may occur during unusual times of day, such as early in the morning or late at night.
It is important to note that not all unusual transactions are fraudulent. There may be legitimate reasons for a transaction to exhibit unusual behavior. However, by identifying transactions that are more likely to be fraudulent, outlier detection algorithms can help to reduce the risk of fraud.
We will discuss different types of anomalies (clustered, local, global, dependent), in different supervision settings (unsupervised, semi-supervised, supervised) and different category of algorithms (graph, support vector, decision tree, density based etc.) in another dedicated post.
Group 3: Semi-supervised Learning, Active Learning

This category of solutions are applicable when you have a large amount of user activity data that hasn’t been evaluated for suspicious behavior (i.e. unlabaled data) and a very small amount of confirmed fraud labels. In short, unlabeled data is abundant and easy to get, while labeled data is expensive and scarce. For example consider the case of Account Takeover fraud: you might not have any team of investigators or risk analysts to find comprimised accounts, but the real user whose account got compromised might reach out to your customer care and complaint about the compromise. This way you will have “Customer Reported Labels”. Such labels might be scarce but are useful.
A. Semi-supervised Learning

Semi-supervised learning (SSL) is a machine learning technique that uses both labeled and unlabeled data to train a model. Unlike fully supervised learning, you don’t really need a lot of labeled data, even many scenarios, even 5-10 labeled events are helpful. Semi supervised learning mitigate some challenges that Anomaly Detection has: i.e. not all anomalies are fraud and not all fraud are anomalies. There have been several research works (Deviation Networks, Deep SAD) that show semi-supervised models even with a dozen of confirmed fraud can outperform unsupervised anomaly detection. You will most certainly find this to be true for your scenario too. The supervision can provide guidance to the learning algorithm on the areas to look for fraudulent behaviors and uses unlabeled data to learn the distribution of normal transactions.
A typical scenario that fits SSL framework looks like following: you have some confirmed safe, some confirmed fraud and lots of unknown user activity data.

The goal of the model is to understand data distribution of what’s normal/safe activity and using that create a decision boundary to differentiate safe vs. suspicious activities. There is a heavy amount of literature in using semi-supervised learning techniques for fraud detection. Jesper Engelen (NVIDIA) has done a great job at summarizing and creating the taxonomy of SSL liteature in his survey paper. In a nutshell, one can try out approaches including self-training, co-training, pseudo labeling, generative models, graph based models, cluster-then-label, mixup, one class classifiers etc. It it out of scope of this post to discuss different techniques within SSL, but I will share implementation of a few relevant papers in the later posts. So stay tuned!
Note that semi-supervised techniques come with challenges that do not make them fit for all scenarios:
- In order for semi-supervised algorithms to work well, the data should have certain properties. These properties include 1: smoothness: if features of any two events are similar, their labels (fraud or legitimate) are also similar, 2: low density: decision boundary that divides fraud and legitimate population in a high dimension feature space passes through low density regions where population is low, 3: cluster: events belonging to same cluster or manifold have same label.
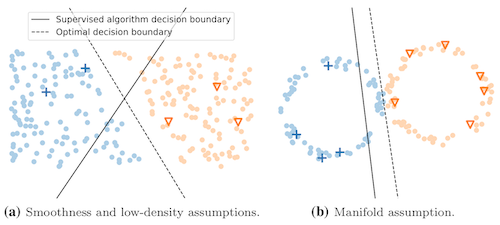
Reference: A survey on semi-supervised learning, Engelen, Jesper and Hoos, Holger
- Its hard to evaluate the performance of models if trained with a handful of labels. How will you create test split for measuring offline performance if all you have is 5 labeled events? The same challenge exists for anomaly detection techniques and one the use same evaluation metrics as in anomaly detection approaches. We will discuss about the choice of evaluation metrics in the next blogpost. So do subscribe to receive notification.
B. Active Learning
Active learning is a technique that uses algorithms to identify and shortlist events that are most likely to be investigated for suspicious activity. This helps investigators to focus on a selected set of events instead of looking at all activities for suspicion. Once the labels are available, a semi-supervised or fully supervised classification model can be built using those. Active learning can be quite useful even with fully developed fraud detection systems as the patterns of fraud constantly keep changing and active learning helps to surface those new patterns.
I copied the following illustration and its explanation from a blogpost titled Active Learning on Fraud Detection written by Miguel Leite. I shamelessly picked it because I thought Miguel did a great job in explaining the active learning framework.
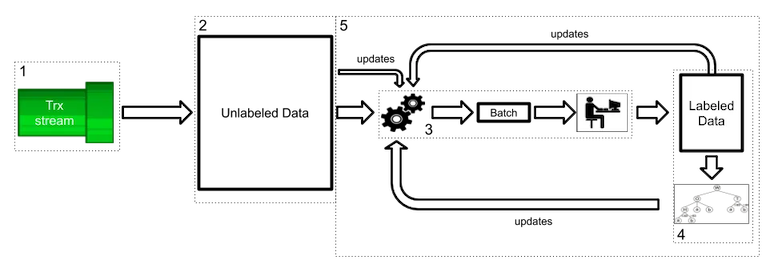 The Active Learning Flow, taken from Active Learning on Fraud Detection by Miguel Leite
The Active Learning Flow, taken from Active Learning on Fraud Detection by Miguel Leite
- The client’s transactions happen in real-time and are represented by the transaction stream.
- As transactions come in through the stream, they are being stored in the unlabeled data pool, where all the unlabeled transactions are stored (i.e., we don’t know which ones are fraud or not). This pool is constantly increasing over time.
- This is the “heart” of the active learning framework. The gears on the left represent an active learning policy, which selects a batch of unlabeled transactions that it considers the most relevant to send to the analysts.
- After being labeled by the analysts, the transactions from the batch, together with their brand-new labels, are added to the labeled data pool. With this pool, we are now capable of training a machine learning model.
- Now we can start iterating. In every iteration, we can use the information available on the labeled pool, the unlabeled pool, and the current model to update the active learning policy, so it can decide which transactions would be the most relevant to label next, increasing the labeled pool.
What you can achieve using active learning?
- Less number of labeled data points to achieve same amount of performance as you would otherwise need to label all of them.
- Save time and improve efficiency of investigators.
- Improved accuracy of fraud detection, a lower number of false positives and false negatives.
You can learn more in the literature review by Burr Settles, titled Active Learning Literature Survey
Group 4. Supervised Classification Algorithms

Now we are talking about the most optimistic scenario, i.e. when a large number of ground truth labels are available. Even within single fraud type, there can be different sub-definitions of fraud but the simplest approach is to classify an activity as either fraudulent (1) or legitimate (0). Given the binary label setting, the most obvious and actually most high performant solution among others we discussed today, is supervised classification framework.
Supervised classification in tabular data setting is modeled most robust and performant with tree based ensembles. Gradient boosting methods like Catboost, LightGBM, XGBoost take the lead. But you need to use some feature engineering tactics to train better models:
Feature engineering tactics for robust results:
1. Window based aggregations and linkages: Almost always, it helps to explicitly create window based aggregations from the user activity data and pass those are features to your classification models. Some examples of these features are:
- number of other transactions from the IP used in the current transaction over last 4 weeks,
- number of logins from the user in last 24 hours,
- country user logged in previous time,
- time when the user performed transaction for the first time,
- location of last order delivery,
- etc.
You can imagine that there can be hundreds of such variables. You can initially start with simpler ones and a single window. Why are such aggregations important?: We personally don’t know the fraudsters and what kind of loopholes or behavior patterns they exhibit. Did they steal someone’s credit card and are placing many orders in short span of time from your e-commerce store? or Did they find someone’s username-password and trying to place orders from their legitimate account to a new location. In the former case, you would see “number of times a card is used in transaction within last 24 hours” (a potential window aggregate) to be very high, much higher than an average legitimate transaction. In the latter case, you would see location of order delivery different than the location of last order delivery. The “distance between current and previous order location” (a potential linkage) would be high, much higher than any legitimate transaction.
2. Supplement your data with external information: You can improve the accuracy and reliability of your raw activity data by adding new and supplemental information from third-party sources. Some raw features can be expanded to supplement with behavioral, demographic or geographic information. Classic example is IP address that can be easily enriched to geolocation, subnet, network, VPN, reputation score and all that supplemental can improve your classification models.
These are good primers for building a decent supervised classification model, it can outperform anomaly detection or semi supervised model. This can be further improved by leveraging the graphical structure of user activities. One way to keep things simple but still use compex relations that neural network can learn is to train a network on data and extract embeddings from the pre-trained network as yet-another-feature for your tree based classifier. You can do following:
Neural network based feature engineering:
1. RNN, Transformer based network for sequential information: The user activities are distributed across time and you get time-series style data. So use RNN or Transformer style architecture for capturing sequential information. If done well, it would do the similar job as window based aggregations. For example, the network can learn from the sequence of sign-ins about how to detect anomalous behaviors that can help in detecting account-takeover fraud.
2. Graph network for neighborhood and likages: The user activities are connected with each other across several attributes. Generally, we use same email address to register in multiple websites, use same card for transactions in various places and use one or two devices (e.g. Mac and iPhone). Similar story is true for fraudsters, but due to their ill will, their behavior would be different than normal users. For e.g. instead of using same card for transactions, they might rotate several cards and use several email addresses to register, but their device might be remain same. You would see multiple of those fraudulent transactions conneted with device as common thread. Graph networks can leverage such connections and provide better information that you might otherwise miss.
OK. That’s it for now in this post. Let’s summarize what we read. Thanks for staying till the end!!
Takeaways
In this post, we discussed about different design frameworks of fraud detection when we want to use machine learning to improve the ability to catch fraud before it occurs. Different organizations are at different stages of the development of their overall fraud prevention systems. Depending on where your organization is at, you can use different ML design framework. For each framework, we touched the surface and saw a 100 ft. view. As a machine learning engineer tasked to empower fraud detection capability, I hope that this post gave you a good mental model to think about the next solution you will need to implement in your organization.
If you found it useful, consider subscribing to receive notification as I will be writing more content like this:
Next up
- Evaluating different techniques before putting in production
- Benchmarking of commonly used algorithms within each framework
- Discussion of latest research works
- Building an MLOps infrastructure to train and deploy the fraud detection models